Cosine Similarity
As you know, to measure similarity between 2 dataset can use several way, maybe you are familiar with Pearson Correlation, Pearson Correlation is a measure two dataset by measuring their Eucledian Distance or the minimum distance.
Another metode is using Cosine Similarity, different with Pearson Correlation, which is sort the similarity from the smallest distance between data in other words same data are similar if their distance is 0, Cosine similarity is the most similar data, then they should closer to 1.
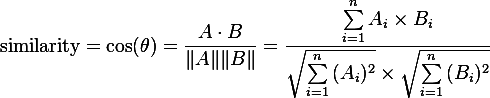
Thats the formula of cosine similarity, you need to calculate cross product the 2 dataset and divide it with normalize every data set. The most closer the result will be 1. BUT, something that need to remember is we must clean the data first, which mean the data that we will use must be the intersection of two data set.
The implementation of Cosine Similarity in Java can be checked in My Github, and i built it using TDD (YEAYYYY AGAIN). For next series of my statistical model, i’ll added it into this repository.