TF IDF
TF IDF is stands for Term Frequency-Inverse Document Factory. Basically the TF IDF will produced a vector of word every document. To calculate tf-idf there is somestep to follow :
- Create the matrix term frequency of word in each document.
example word : “I am very sleepy, and i want to go to bed”
the term frequency matrix is :
I = 2
am = 1
very = 1
sleepy = 1
and = 1
want= 1
to = 2
go = 1
bed = 1

- Inverse the document frequency.
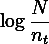
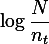
you can use that formula by logaritmic count of row every word divide count of row when the count of word is more than 0.

Calculate the tf idf
After that calculate matrix tf and matrix idf

Normalize the Tf-idf
as you see, the result of tf-idf is not normal distributed. So we need 2 step to normalize the tf-idf :

- find the weight / divider for every word.
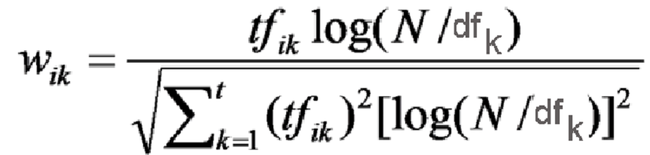
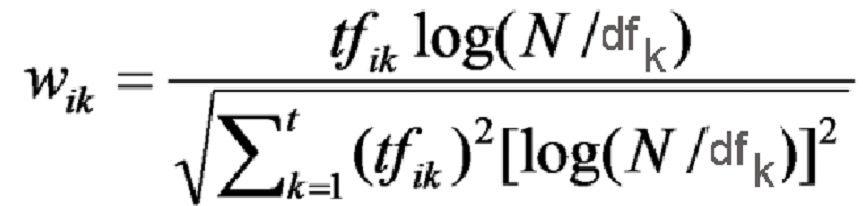

- divide the Tf-idf every document with the weight of the document


after we found the normal distribution we can measure distance every document by using cosine similiarity
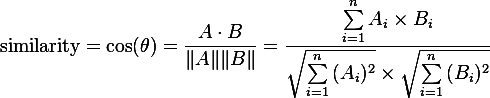
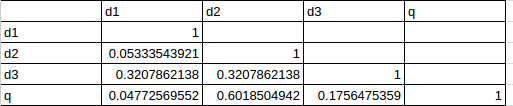
This is the result after comparing each document
you can see the calculation in my google docs. As you know, for me i’m not knowing something if i can’t transform that into code. So in next several days i’ll put some code in repo and post it in my blog.